









Google researchers have come up with a new AutoML framework, which can automatically learn high-quality models with minimal expert intervention. Google AdaNet is a fast, flexible, and lightweight TensorFlow-based framework for learning a neural network architecture and learning to ensemble to obtain even better models.
How Google Adanet works?
As machine learning models increase in number, Adanet will automatically search over neural architectures, and learn to combine the best ones into a high-quality model. Adanet implements an adaptive algorithm for learning a neural architecture as an ensemble of subnetworks. It can add subnetworks of different depths and widths to create a diverse ensemble, and trade off performance improvement with the number of parameters. This saves ML engineers the time spent selecting optimal neural network architectures.
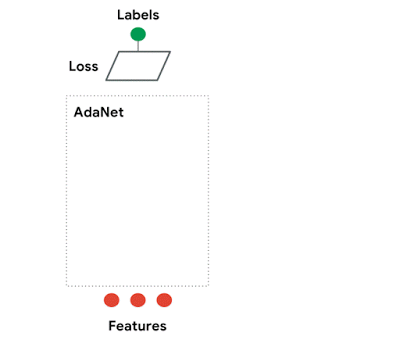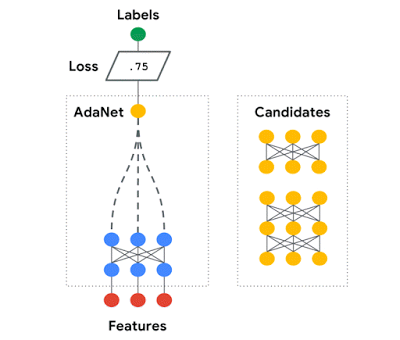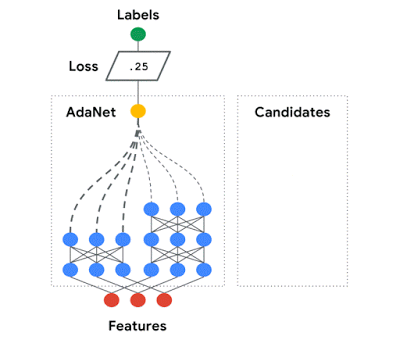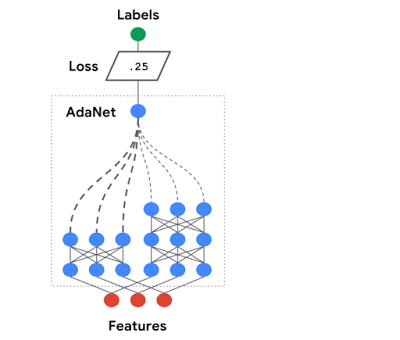
Source: Google
Adanet: Built on Tensorflow
AdaNet implements the TensorFlow Estimator interface. This interface simplifies machine learning programming by encapsulating training, evaluation, prediction and export for serving. Adanet also integrates with open-source tools like TensorFlow Hub modules, TensorFlow Model Analysis, and Google Cloud’s Hyperparameter Tuner. TensorBoard integration helps to monitor subnetwork training, ensemble composition, and performance. Tensorboard is one of the best TensorFlow features for visualizing model metrics during training. When AdaNet is done training, it exports a SavedModel that can be deployed with TensorFlow Serving.
How to extend AdaNet to your own projects
Machine learning engineers and enthusiasts can define their own AdaNet adanet.subnetwork.Builder using high level TensorFlow APIs like tf.layers. Users who have already integrated a TensorFlow model in their system can use the adanet.Estimator to boost model performance while obtaining learning guarantees. Users are also invited to use their own custom loss functions via canned or custom tf.contrib.estimator.Heads in order to train regression, classification, and multi-task learning problems. Users can also fully define the search space of candidate subnetworks to explore by extending the adanet.subnetwork.Generator class.
Experiments: NASNet-A versus AdaNet
Google researchers took an open-source implementation of a NASNet-A CIFAR architecture and transformed it into a subnetwork. They were also able to improve upon CIFAR-10 results after eight AdaNet iterations. The model achieves this result with fewer parameters:

Source: Google
You can checkout the Github repo, and walk through the tutorial notebooks for more details. You can also have a look at the research paper.
Read Next
Top AutoML libraries for building your ML pipelines.