
Yesterday, researchers at Facebook introduced a machine learning system named, Rosetta for scalable optical character recognition (OCR). This model extracts text from more than a billion public Facebook and Instagram images and video frames. Then, this extracted text is fed into a text recognition model that has been trained on classifiers, which helps it understand the context of the text and the image together.
Why Rosetta is introduced?
Rosetta will help in the following scenarios:
- Provide a better user experience by giving users more relevant photo search results.
- Make Facebook more accessible for the visually impaired by incorporating the texts into screen readers.
- Help Facebook proactively identify inappropriate or harmful content.
- Help to improve the accuracy of classification of photos in News Feed to surface more personalized content.
How it works?

Rosetta consists of the following text extraction model:
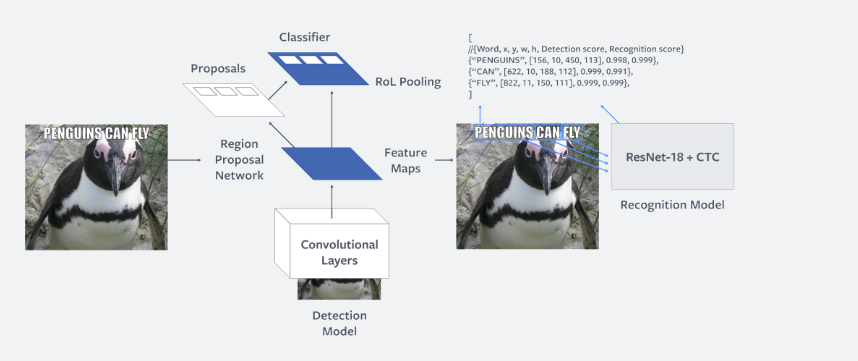
Text extraction on an image is done in the following two steps:
Text detection
In this step, rectangular regions that potentially contain the text are detected. It performs text detection based on Faster R-CNN, a state-of-the-art object detection network.
It uses Faster R-CNN but replaces ResNet convolutional body with a ShuffleNet-based architecture for efficiency reasons. The anchors in regional proposal network (RPN) are also modified to generate wider proposals, as text words are typically wider than the objects for which the RPN was designed.
The whole detection system is trained jointly in a supervised, end-to-end manner. The model is bootstrapped with an in-house synthetic data set and then fine-tuned with human-annotated data sets so that it learns real-world characteristics. It is trained using the recently open-sourced Detectron framework powered by Caffe2.
Text recognition
The following image shows the architecture of the text recognition model:

In the second step, for each of the detected regions a convolutional neural network (CNN) is used to recognize and transcribe the word in the region. This model uses CNN based on the ResNet18 architecture, as this architecture is more accurate and computationally efficient.
For training the model, finding what the text in an image says is considered as a sequence prediction problem. They input images containing the text to be recognized and the output generated is the sequence of characters in the word image. Treating the model as one of sequence prediction allows the system to recognize words of arbitrary length and to recognize the words that weren’t seen during training.
This two-step model provides several benefits, including decoupling the training process of detection and recognition models, recognition of words in parallel, and independently supporting text recognition for different languages.
Rosetta has been widely adopted by various products and teams within Facebook and Instagram. It offers a cloud API for text extraction from images and processes a large volume of images uploaded to Facebook every day. In future, the team is planning to extend this system to extract text from videos more efficiently and also support a wide number of languages used on Facebook.
To get a more in-depth idea of how Rosetta works, check out the researchers’ post at Facebook code blog and also read this paper: Rosetta: Large Scale System for Text Detection and Recognition in Images.
Read Next
Why learn machine learning as a non-techie?
Is the machine learning process similar to how humans learn?