









A California-based AI startup, Cerebras Systems has unveiled the largest semiconductor chip ever built named as the ‘Wafer Scale Engine’ built to quickly train deep learning models.
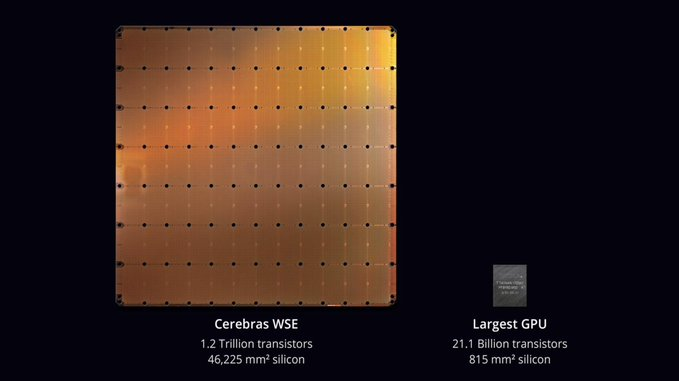
The Cerebras Wafer Scale Engine (WSE) is 46,225 millimeters square, contains more than 1.2 trillion transistors. It is “more than 56X larger than the largest graphics processing unit, containing 3,000X more on-chip memory and more than 10,000X the memory bandwidth,” the whitepaper reads.
Most of the chips available today include a collection of chips built on top of a 12-inch silicon wafer and are processed in a chip factory in a batch. However, the WSE chip is interconnected on a single wafer. “The interconnections are designed to keep it all functioning at high speeds so the trillion transistors all work together as one,” Venture Beats reports.
Andrew Feldman, co-founder and CEO of Cerebras system said, “Designed from the ground up for AI work, the Cerebras WSE contains fundamental innovations that advance the state-of-the-art by solving decades-old technical challenges that limited chip size — such as cross-reticle connectivity, yield, power delivery, and packaging.” He further adds, “Every architectural decision was made to optimize performance for AI work. The result is that the Cerebras WSE delivers, depending on workload, hundreds or thousands of times the performance of existing solutions at a tiny fraction of the power draw and space.”
According to Wired, “Cerebras’ chip covers more than 56 times the area of Nvidia’s most powerful server GPU, claimed at launch in 2017 to be the most complex chip ever. Cerebras founder and CEO Andrew Feldman says the giant processor can do the work of a cluster of hundreds of GPUs, depending on the task at hand, while consuming much less energy and space.”
Source: Twitter
In the whitepaper, Feldman explains, for maximum performance, the entire model should fit in the fastest memory, which is the memory closest to the computation cores. This is not the case in CPUs, TPUs, and GPUs, where main memory is not integrated with compute. Instead, the vast majority of memory is based off-chip, far away on separate DRAM chips or a stack of these chips in a high bandwidth memory (HBM) device. As a result, the main memory is excruciatingly slow.
The dawn of AI brought in an added consumption of higher processing power which gave rise to the demand of GPUs. However, even if a machine is filled with dozens of Nvidia’s graphics chips or GPUs, “it can take weeks to “train” a neural network, the process of tuning the code so that it finds a solution to a given problem,” according to Fortune.
Linley Gwennap, a chip observer who publishes a distinguished chip newsletter, Microprocessor Report told Fortune that bundling together multiple GPUs in a computer starts to show diminishing returns once more than eight of the chips are combined. Feldman further adds “The hard part is moving data.”
While training a neural network, thousands of operations happen in parallel. Also, chips must constantly share data as they crunch those parallel operations. However, computers with multiple chips may face performance issues while trying to pass data back and forth between the chips over the slower wires that link them on a circuit board. The solution Feldman said was to “take the biggest wafer you can find and cut the biggest chip out of it that you can.”
Per Fortune, “the chip won’t be sold on its own but will be packaged into a computer “appliance” that Cerebras has designed. One reason is the need for a complex system of water-cooling, a kind of irrigation network to counteract the extreme heat generated by a chip running at 15 kilowatts of power.” “The wafers were produced in partnership with Taiwan Semiconductor Manufacturing, the world’s largest chip manufacturer, but Cerebras has exclusive rights to the intellectual property that makes the process possible.”
J.K. Wang, TSMC’s senior vice president of operations said, “We are very pleased with the result of our collaboration with Cerebras Systems in manufacturing the Cerebras Wafer Scale Engine, an industry milestone for wafer-scale development.” “TSMC’s manufacturing excellence and rigorous attention to quality enable us to meet the stringent defect density requirements to support the unprecedented die size of Cerebras’ innovative design.”
The whitepaper explains that 400,000 cores on Cerebras WSE are connected via a Swarm communication fabric in a 2D mesh with 100 Petabits per second of bandwidth. Swarm provides a hardware routing engine to each of the compute cores and connects them with short wires optimized for latency and bandwidth.
Feldman said that “a handful” of customers are trying the chip, including on drug design problems. He plans to sell complete servers built around the chip, rather than chips on their own but declined to discuss price or availability.
Many find this announcement interesting given the number of transistors in work on the wafer engine. A few are skeptical if this chip will live up to the expectation.
A user on Reddit commented, “I think this is fascinating. If things go well with node scaling and on-chip non-volatile memory, by mid 2030 we could be approaching human brain densities on a single ‘chip’ without even going 3D. It’s incredible.”
A user on HackerNews writes, “In their whitepaper, they claim “with all model parameters in on-chip memory, all of the time,” yet that entire 15 kW monster has only 18 GB of memory.
Given the memory vs compute numbers that you see in Nvidia cards, this seems strangely low.”
1/ Cerebras just built a chip with 50x the transistor count, 1,000x the memory and 10,000x the bandwidth of Nvidia’s flagship GPU. One such 'chip' could replace an entire rack of Nvidia GPUs.
What the heck is going on? pic.twitter.com/Rs0FaAzLUS
— James Wang (@jwangARK) August 20, 2019
12/ Healthy skepticism is warranted. The industry has never seen anything like this before. It might not live up to these lofty goals for all kinds of reasons. Cerebras says they have customers in trials now and official benchmarks in November so we’ll see.
— James Wang (@jwangARK) August 20, 2019
To know more about Cerebras WSE chip in detail, read the complete whitepaper.