









Earlier this month, Dirk Lewandowski, Professor of Information Research & Information Retrieval at Hamburg University of Applied Sciences, Germany, published a proposal for building an index of the Web. His proposal aims to separate the infrastructure part of search engine from the services part.
Search engines are our way to the web, which makes them an integral part of the Web’s infrastructure. While there are a significant number of search engines present in the market, there are only a few relevant search engines that have their own index, for example, Google, Bing, Yandex and Baidu. Other search engines that pull results from these search engines, for instance, Yahoo, cannot really be considered search engines in the true sense.
The US search engine market is split between Google and Bing with roughly two thirds to one-third, respectively, In most European countries, Google covers the 90% of the market share. Highlighting the implications of Google’s dominance in the current search engine market, the report reads, “As this situation has been stable over at least the last few years, there have been discussions about how much power Google has over what users get to see from the Web, as well as about anti-competitive business practices, most notably in the context of the European Commission’s competitive investigation into the search giant.”
The proposal aims to bring plurality in the search engine market, not only in terms of the numbers of search engine providers but also in the number of search results users get to see when using search engines.
The idea is to implement the “missing part of the Web’s infrastructure” called searchable index. The author proposes to separate the infrastructure part of the search engine from services part. This will allow multitude of services, whether existing as search engines or otherwise to be run on a shared infrastructure.
The following figure shows how the public infrastructure crawls the web for indexing its content and provides an interface to the services that are built on top of the index. The indexing stage is split into basic indexing and advanced indexing. Basic indexing is responsible for providing the data in a form that services built on top of the index can easily and rapidly process the data. Though services are allowed to do their further indexing to prepare the documents, the open infrastructure also provides some advanced indexing. This provides additional information to the indexed documents, for example, semantic annotations.
This advanced indexing requires an extensive infrastructure for data mining and processing. Services will be able to decide for themselves to what extent they want to rely on the pre-processing infrastructure provided by the Open Web Index. A common design principle can be adopted is allowing services a maximum of flexibility.
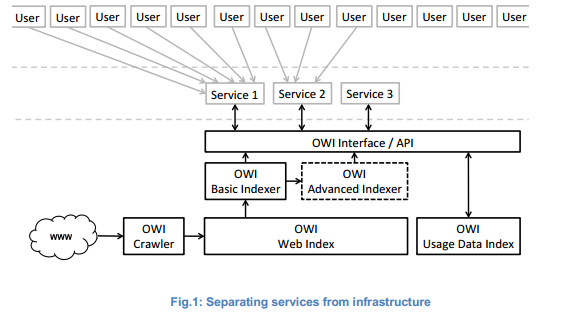
Credits: arXiv
Many users are supporting this idea. One Redditor said, “I have been wanting this for years…If you look at the original Yahoo Page when Yahoo first started out it attempted to solve this problem.I believe this index could be regionally or language based.”
Some others do believe that implementing an open web index will come with its own challenges. “One of the challenges of creating a “web index” is first creating indexes of each website. “Crawling” to discover every page of a website, as well as all links to external sites, is labour-intensive and relatively inefficient. Part of that is because there is no 100% reliable way to know, before we begin accessing a website, each and every URL for each and every page of the site. There are inconsistent efforts such “site index” pages or the “sitemap” protocol (introduced by Google), but we cannot rely on all websites to create a comprehensive list of pages and to share it,” adds another Redditor.
To read more in detail, check out the paper titled: The Web is missing an essential part of infrastructure: an Open Web Index.
Read Next
Google Cloud Next’19 day 1: open-source partnerships, hybrid-cloud platform, Cloud Run, and more
Dark Web Phishing Kits: Cheap, plentiful and ready to trick you


