









Yesterday, the BlazingSQL team open-sourced BlazingSQL under the Apache 2.0 license. It is a lightweight, GPU-accelerated SQL engine built on top of the RAPIDS.ai ecosystem. RAPIDS.ai is a suite of software libraries and APIs for end-to-end execution of data science and analytics pipelines entirely on GPUs.
Explaining his vision behind this step, Rodrigo Aramburu, CEO of BlazingSQL wrote in a Medium blog post, “As RAPIDS adoption continues to explode, open-sourcing BlazingSQL accelerates our development cycle, gets our product in the hands of more users, and aligns our licensing and messaging with the greater RAPIDS.ai ecosystem.”
Aramburu calls RAPIDS “the next-generation analytics ecosystem” where BlazingSQL serves as the SQL standard. It also serves as an SQL interface for cuDF, a GPU DataFrame (GDF) library for loading, joining, aggregating, and filtering data.
Here’s an overview of how BlazingSQL fits into the RAPIDS.ai ecosystem:
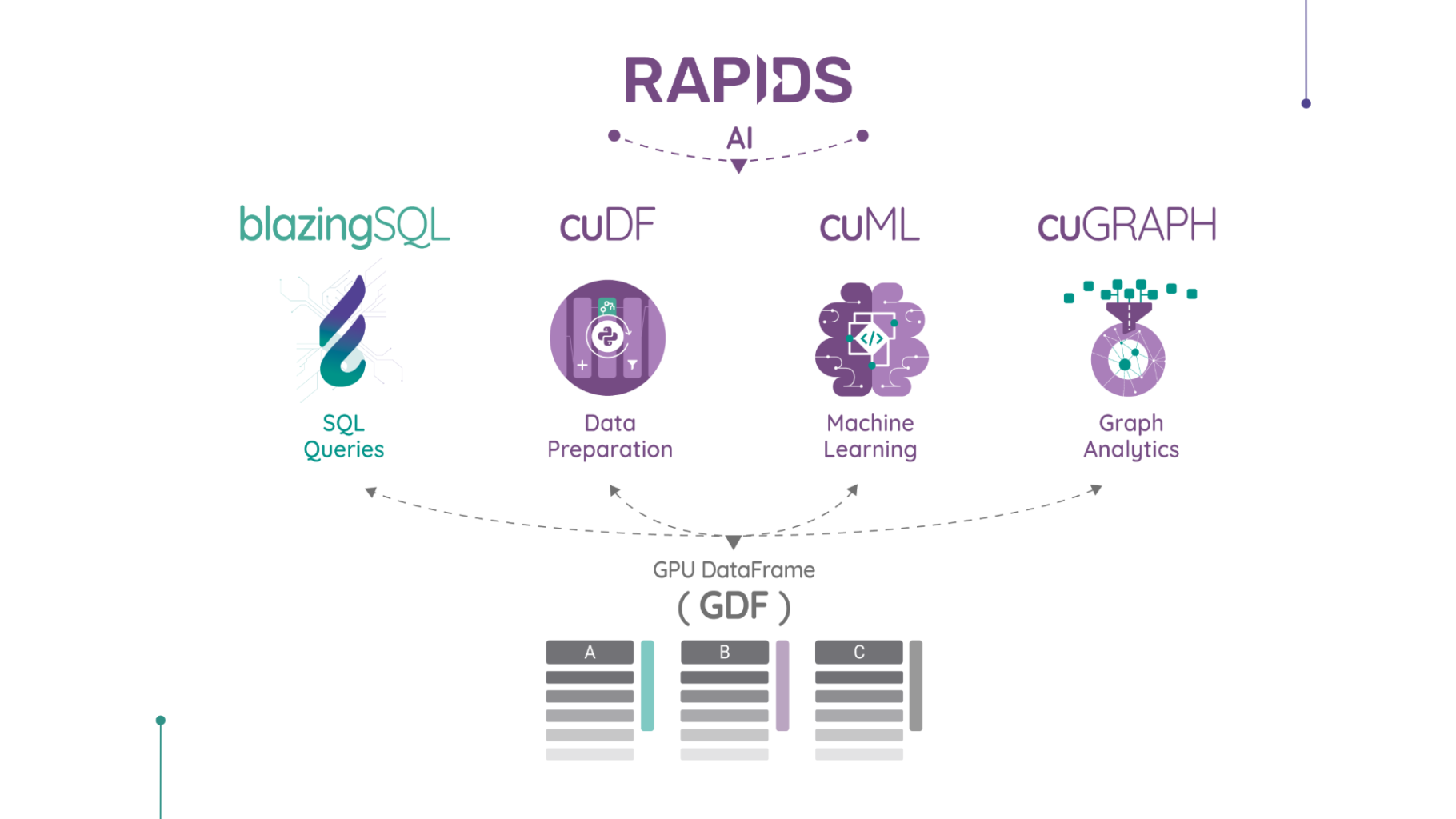
Source: BlazingSQL
Advantages of using BlazingSQL
- Cost-effective: Customers often have to cluster thousands of servers for processing data at scale, which can be very expensive. BlazingSQL takes up only a small fraction of the infrastructure to run at an equivalent scale.
- Better performance: BlazingSQL is 20x faster than Apache Spark cluster when extracting, transforming, and loading data. It generates GPU-accelerated results in seconds enabling data scientists to quickly iterate over new models.
- Easily scale up workload: Usually, workloads are first prototyped at small scale and then rebuilt for distributed systems. With BlazingSQL, you need to write code only once that can be dynamically changed depending on the scale of distribution with minimal code changes.
- Connect to multiple data sources: It connects to multiple data sources for querying files in local and distributed filesystems. Currently, it supports AWS S3 and Apache HDFS and the team plans to support more in the future.
- Run federated queries: It allows you to directly query raw data into GPU memory in its original format with the help of federated queries. A federated query allows you to join data from multiple data stores across multiple data formats. It currently supports CSV, Apache Parquet, JSON, and existing GPU DataFrames.
GM of data science at NVIDIA, Josh Patterson said in the announcement, “NVIDIA and the RAPIDS ecosystem are delighted that BlazingSQL is open-sourcing their SQL engine built on RAPIDS. By leveraging Apache Arrow on GPUs and integrating with Dask, BlazingSQL will extend open-source functionality, and drive the next wave of interoperability in the accelerated data science ecosystem.”
This news sparked a discussion on Hacker News, where Aramburu cleared any queries developers had about BlazingSQL. One developer asked why the team chose CUDA instead of an open-sourced option like OpenCL. Aramburu explained, “Early on when we first started playing around with General Processing on GPU’s we had Nvidia cards to begin with and I started looking at the APIs that were available to me.
The CUDA ones were easier for me to get started, had tons of learning content that Nvidia provided, and were more performant on the cards that I had at the time compared to other options. So we built up lots of expertise in this specific way of coding for GPUS. We also found time and time again that it was faster than OpenCL for what we were trying to do and the hardware available to us on cloud providers was Nvidia GPUs.
The second answer to this question is that blazingsql is part of a greater ecosystem. rapids.ai and the largest contributor by far is Nvidia. We are really happy to be working with their developers to grow this ecosystem and that means that the technology will probably be CUDA only unless we somehow program “backends” like they did with thrust but that would be eons away from now.”
People also celebrated the news of Blazing SQL’s open-sourcing. A comment on Hacker News reads, “This is great. The BlazingDB guys are awesome and now that the project is open source this is another good reason for my teams to experiment with different workloads and compare it against a SparkSQL approach”
Read Next
BlazingDB announces BlazingSQL , a GPU SQL Engine for NVIDIA’s open source RAPIDS
Amazon Aurora makes PostgreSQL Serverless generally available