Background
Why choose K8s for Apache Spark
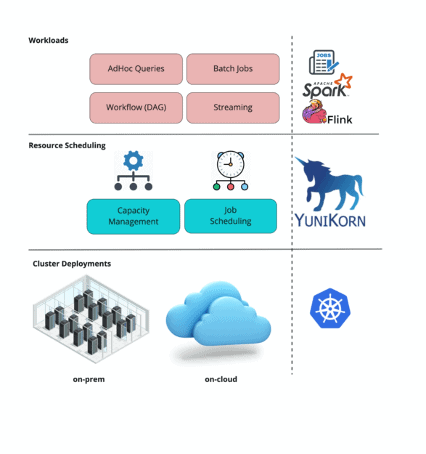
Apache Spark unifies batch processing, real-time processing, stream analytics, machine learning, and interactive query in one-platform. While Apache Spark provides a lot of capabilities to support diversified use cases, it comes with additional complexity and high maintenance costs for cluster administrators. Let’s look at some of the high-level requirements for the underlying resource orchestrator to empower Spark as a one-platform:
- Containerized Spark compute to provide shared resources across different ML and ETL jobs
- Support for multiple Spark versions, Python versions, and version-controlled containers on the shared K8s clusters for both faster iteration and stable production
- A single, unified infrastructure for both majority of batch workloads and microservices
- Fine-grained access controls on shared clusters
Kubernetes as a de-facto standard for service deployment offers finer control on all of the above aspects compared to other resource orchestrators. Kubernetes offers a simplified way to manage infrastructure and applications with a practical approach to isolate workloads, limit the use of resources, deploy on-demand resources, and auto-scaling capabilities as needed.
Scheduling challenges to run Apache Spark on K8s
Kubernetes default scheduler has gaps in terms of deploying batch workloads efficiently in the same cluster where long-running services are also to be scheduled. Batch workloads need to be scheduled mostly together and much more frequently due to the nature of compute parallelism required. Let’s look at some of those gaps in detail.
Lack of first-class application concept
Batch jobs often need to be scheduled in a sequential manner based on types of container deployment. For instance, Spark driver pods need to be scheduled earlier than worker pods. A clear first-class application concept could help with ordering or queuing each container deployment. Also, such a concept helps admin to visualize the jobs which are scheduled for debugging purposes.
Lack of efficient capacity/quota management capability
Kubernetes namespace resource quota can be used to manage resources while running a Spark workload in multi-tenant use cases. However, there are few challenges in achieving this,
- Apache Spark jobs are dynamic in nature with regards to their resource usage. Namespace quotas are fixed and checked during the admission phase. The pod request is rejected if it does not fit into the namespace quota. This requires the Apache Spark job to implement a retry mechanism for pod requests instead of queueing the request for execution inside Kubernetes itself.
- The namespace resource quota is flat, it doesn’t support hierarchy resource quota management.
Also many a time, user’s could starve to run the batch workloads as Kubernetes namespace quotas often do not match the organizational hierarchy based capacity distribution plan. An elastic and hierarchical priority management for jobs in K8s is missing today.
Lack of resource fairness between tenants
In a production environment, it is often found that Kubernetes default scheduler could not efficiently manage diversified workloads and provide resource fairness for their workloads. Some of the key reasons are:
- Batch workload management in a production environment will often be running with a large number of users.
- In a dense production environment where different types of workloads are running, it is highly possible that Spark driver pods could occupy all resources in a namespace. Such scenarios pose a big challenge in effective resource sharing.
- Abusive or corrupted jobs could steal resources easily and impact production workloads.
Strict SLA requirements with scheduling latency
Most of the busy production clusters dedicated for batch workloads often run thousands of jobs with hundreds of thousands of tasks every day. These workloads require larger amounts of parallel container deployments and often the lifetime of such containers is short (from seconds to hours). This usually produces a demand for thousands of pod or container deployment waiting to be scheduled, using Kubernetes default scheduler can introduce additional delays which could lead to missing of SLAs.
How Apache YuniKorn (Incubating) could help
Overview of Apache YuniKorn (Incubating)
YuniKorn is an enhanced Kubernetes scheduler for both services and batch workloads. YuniKorn can replace Kubernetes default scheduler, or also work with K8s default scheduler based on the deployment use cases.
YuniKorn brings a unified, cross-platform scheduling experience for mixed workloads consisting of stateless batch workloads and stateful services.
YuniKorn v.s. Kubernetes default scheduler: A comparison
| Feature |
Default
Scheduler
|
YUNIKORN |
Note |
| Application concept |
x |
√ |
Applications are a 1st class citizen in YuniKorn. YuniKorn schedules apps with respect to, e,g their submission order, priority, resource usage, etc. |
| Job ordering |
x |
√ |
YuniKorn supports FIFO/FAIR/Priority (WIP) job ordering policies |
| Fine-grained resource capacity management |
x |
√ |
Manage cluster resources with hierarchy queues. Queues provide the guaranteed resources (min) and the resource quota limit (max). |
| Resource fairness |
x |
√ |
Resource fairness across application and queues to get ideal allocation for all applications running |
| Natively support Big Data workloads |
x |
√ |
Default scheduler focuses for long-running services. YuniKorn is designed for Big Data app workloads, and it natively supports to run Spark/Flink/Tensorflow, etc efficiently in K8s. |
| Scale & Performance |
x |
√ |
YuniKorn is optimized for performance, it is suitable for high throughput and large scale environments. |
How YuniKorn helps to run Spark on K8s
YuniKorn has a rich set of features that help to run Apache Spark much efficiently on Kubernetes. Detailed steps can be found here to run Spark on K8s with YuniKorn.
Please read more details about how YuniKorn empowers running Spark on K8s in Cloud-Native Spark Scheduling with YuniKorn Scheduler in Spark & AI summit 2020.
Let’s take a look at some of the use cases and how YuniKorn helps to achieve better resource scheduling for Spark in these scenarios.
Multiple users (noisy) running different spark workloads together
As more users start to run jobs together, it becomes very difficult to isolate and provide required resources for the jobs with resource fairness, priority etc. YuniKorn scheduler provides an optimal solution to manage resource quotas by using resource queues.

In the above example of a queue structure in YuniKorn, namespaces defined in Kubernetes are mapped to queues under the Namespaces parent queue using a placement policy. The Test and Development queue have fixed resource limits. All other queues are only limited by the size of the cluster. Resources are distributed using a Fair policy between the queues, and jobs are scheduled FIFO in the production queue.
Unlock access to the largest independent learning library in Tech for FREE!
Get unlimited access to 7500+ expert-authored eBooks and video courses covering every tech area you can think of.
Renews at $19.99/month. Cancel anytime
Some of the high-level advantages are,
- One YuniKorn queue can map to one namespace automatically in Kubernetes
- Queue Capacity is elastic in nature which could provide resource range from a configured min to max value
- Honor resource fairness which could avoid possible resource starvation
YuniKorn provides a seamless way to manage resource quota for a Kubernetes cluster, it can work as a replacement of the namespace resource quota. YuniKorn resource quota management allows leveraging queuing of pod requests and sharing of limited resources between jobs based on pluggable scheduling policies. This all can be achieved without any further requirements, like retrying pod submits, on Apache Spark.
Setting up the cluster to organization hierarchy based resource allocation model
In a large production environment, multiple users will be running various types of workloads together. Often these users are bound to consume resources based on the organization team hierarchy budget constraints. Such a production setup helps for efficient cluster resource usage within resource quota boundaries.
YuniKorn provides an ability to manage resources in a cluster with a hierarchy of queues. A fine-grained resource capacity management for a multi-tenant environment will be possible by using resource queues with clear hierarchy (like organization hierarchy). YuniKorn queues can be statically configured or dynamically managed and with the dynamic queue management feature, users can set up placement rules to delegate queue management.
Better Spark job SLA in a multi-tenant cluster
Normal ETL workloads running in a multi-tenant cluster require easier means of defining fine-grained policies to run jobs in the desired organizational queue hierarchy. Many times, such policies help to define stricter SLA’s for job execution.
YuniKorn empowers administrators with options to enable the Job ordering in queues based on simpler policies such as FIFO, FAIR, etc. The StateAware app sorting policy orders jobs in a queue in FIFO order and schedules them one by one on conditions. This avoids the common race condition while submitting lots of batch jobs, e.g Spark, to a single namespace (or cluster). By enforcing the specific ordering of jobs, it also improves the scheduling of jobs to be more predictable.
Enable various K8s feature sets for Apache Spark Job scheduling
YuniKorn is fully compatible with K8s major released versions. Users can swap the scheduler transparently on an existing K8s cluster. YuniKorn fully supports all the native K8s semantics that can be used during scheduling, such as label selector, pod affinity/anti-affinity, taints/toleration, PV/PVCs, etc. YuniKorn is also compatible with the management commands and utilities, such as cordon nodes, retrieving events via kubectl, etc.
Apache YuniKorn (Incubating) in CDP
Cloudera’s CDP platform offers Cloudera Data Engineering experience which is powered by Apache YuniKorn (Incubating).
Some of the high-level use cases solved by YuniKorn at Cloudera are,
- Provide resource quota management for CDE virtual clusters
- Provide advanced job scheduling capabilities for Spark
- Responsible for both micro-service and batch jobs scheduling
- Running on Cloud with auto-scaling enabled
Future roadmaps to better support Spark workloads
YuniKorn community is actively looking into some of the core feature enhancements to support Spark workloads execution. Some of the high-level features are
For Spark workloads, it is essential that a minimum number of driver & worker pods be allocated for better efficient execution. Gang scheduling helps to ensure a required number of pods be allocated to start the Spark job execution. Such a feature will be very helpful in a noisy multi-tenant cluster deployment. For more details, YUNIKORN-2 Jira is tracking the feature progress.
Job/Task priority support
Job level priority ordering helps admin users to prioritize and direct YuniKorn to provision required resources for high SLA based job execution. This also gives more flexibility for effective usage of cluster resources. For more details, YUNIKORN-1 Jira is tracking the feature progress.
Distributed Tracing
YUNIKORN-387 leverages Open Tracing to improve the overall observability of the scheduler. With this feature, the critical traces through the core scheduling cycle can be collected and persisted for troubleshooting, system profiling, and monitoring.
Summary
YuniKorn helps to achieve fine-grained resource sharing for various Spark workloads efficiently on a large scale, multi-tenant environments on one hand and dynamically brought up cloud-native environments on the other.
YuniKorn, thus empowers Apache Spark to become an enterprise-grade essential platform for users, offering a robust platform for a variety of applications ranging from large scale data transformation to analytics to machine learning.
Acknowledgments
Thanks to Shaun Ahmadian and Dale Richardson for reviewing and sharing comments. A huge thanks to YuniKorn open source community members who helped to get these features to the latest Apache release.
The post Apache Spark on Kubernetes: How Apache YuniKorn (Incubating) helps appeared first on Cloudera Blog.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand














