In this article by Mike, author of the book Mastering Apache Spark many Hadoop-based tools built on Hadoop CDH cluster are introduced.
(For more resources related to this topic, see here.)
His premise, when approaching any big data system, is that none of the components exist in isolation. There are many functions that need to be addressed in a big data system with components passing data along an ETL (Extract Transform and Load) chain, or calling the subcomponents to carry out processing. Some of the functions are:
- Data Movement
- Scheduling
- Storage
- Data Acquisition
- Real Time Data Processing
- Batch Data Processing
- Monitoring
- Reporting
This list is not exhaustive, but it gives you an idea of the functional areas that are involved. For instance, HDFS (Hadoop Distributed File System) might be used for storage, Oozie for scheduling, Hue for monitoring, and Spark for real-time processing. His point, though, is that none of these systems exists in isolation; they either exist in an ETL chain when processing data, and rely on other sub components as in Oozie, or depend on other components to provide functionality that they do not have.
His contention is that integration between big data systems is an important factor. One needs to consider from where the data is coming, how it will be processed, and where it is then going to. Given this consideration, the integration options for a big data component need to be investigated both, in terms of what is available now, and what might be available in the future.
In the book, the author has distributed the system functionality by chapters, and tried to determine what tools might be available to carry out these functions. Then, with the help of simple examples by using code and data, he has shown how the systems might be used together.
The book is based upon Apache Spark, so as you might expect, it investigates the four main functional modules of Spark:
- MLlib for machine learning
- Streaming for the data stream processing
- SQL for data processing in a tabular format
- GraphX for graph-based processing
However, the book attempts to extend these common, real-time big data processing areas by examining extra areas such as graph-based storage and real-time cloud-based processing via Databricks. It provides examples of integration with external tools, such as Kafka and Flume, as well as Scala-based development examples.
In order to Spark your interest, and prepare you for the book's contents, he has described the contents of the book by subject, and given you a sample of the content.
Overview
The introduction sets the scene for the book by examining topics such as Spark cluster design, and the choice of cluster managers. It considers the issues, affecting the cluster performance, and explains how real-time big data processing can be carried out in the cloud. The following diagram, describes the topics that are explained in the book:
- The Spark Streaming examples are provided along with details for checkpointing to avoid data loss. Installation and integration examples are provided for Kafka (messaging) and Flume (data movement).
- The functionality of Spark MLlib is extended via 0xdata H2O, and a deep learning example neural system is created and tested.
- The Spark SQL is investigated, and integrated with Hive to show that Spark can become a real-time processing engine for Hive.
- Spark storage is considered, by example, using Aurelius (Datastax) Titan along with underlying storage in HBase and Cassandra.
- The use of Tinkerpop and Gremlin shell are explained by example for graph processing.
- Finally, of course many, methods of integrating Spark to HDFS are shown with the help of an example.
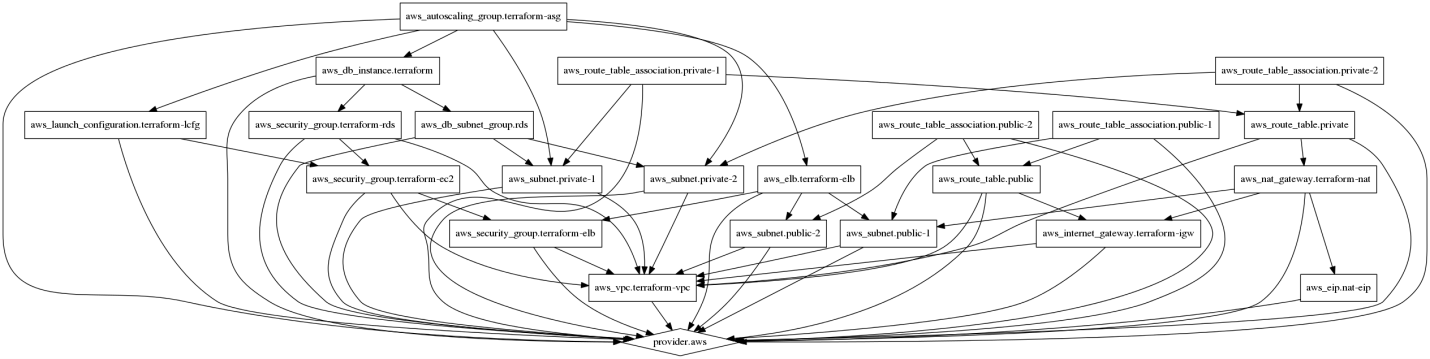
This gives you a flavor of what is in the book, but it doesn't give you the detail. Keep reading to find out what is in each area.
Spark MLlib
Spark MLlib examines data classification with Naïve Bayes, data clustering with K-Means, and neural processing with ANN (Artificial Neural Network). If these terms do not mean anything to you, don't worry. They are explained both, in terms of theory, and then practically with examples.
The author has always been interested in neural networks, and was pleased to be able to base the ANN section on the work by Bert Greevenbosch (www.bertgreevenbosch.nl). This allows to show how Apache Spark can be built from source code, and be extended in the same process with extra functionality. The following diagram shows a real, biological neuron to the left, and a simulated neuron to the right. It also explains how computational neurons are simulated in a step-by-step process from real neurons in your head. It then goes on to describe how neural networks are created, and how processing takes place. It's an interesting topic. The integration of big data systems, and neural processing.
Spark Streaming
An important issue, when processing stream-based data, is failure recover. Here, we examine error recovery, and checkpointing with the help of an example for Apache Spark. It also provides examples for TCP, file, Flume, and Kafka-based stream processing using Spark. Even though he has provided step-by-step, code-based examples, data stream processing can become complicated. He has tried to reduce complexity, so that learning does not become a challenge. For example, when introducing a Kafka-based example, The following diagram is used to explain the test components with the data flow, and the component set up in a logical, step-by-step manner:
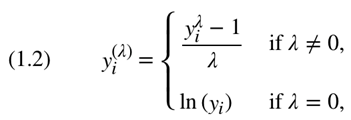
Unlock access to the largest independent learning library in Tech for FREE!
Get unlimited access to 7500+ expert-authored eBooks and video courses covering every tech area you can think of.
Renews at $19.99/month. Cancel anytime
Spark SQL
When introducing Spark SQL, he has described the data file formats that might be used to assist with data integration. Then move on to describe with the help of an example the use of the data frames, followed closely by practical SQL examples. Finally, integration with Apache Hive is introduced to provide big data warehouse real-time processing by example. The user-defined functions are also explained, showing how they can be defined in multiple ways, and be used with Spark SQL.
Spark GraphX
Graph processing is examined by showing how a simple graph can be created in Scala. Then, sample graph algorithms are introduced like PageRank and Triangles. With permission from Kenny Bastani (http://www.kennybastani.com/), the Mazerunner prototype application is discussed. A step-by-step approach is described by which Docker, Neo4j, and Mazerunner can be installed. Then, the functionality of both, Neo4j and Mazerunner, is used to move the data between Neo4j and HDFS. The following diagram gives an overview of the architecture that will be introduced:
Spark storage
Apache Spark is a highly functional, real-time, distributed big data processing system. However, it does not provide any data storage. In many places within the book, the examples are provided for using HDFS-based storage, but what if you want graph-based storage? What if you want to process and store data as a graph? The Aurelius (Datastax) Titan graph database is examined in the book. The underlying storage options with Cassandra, and HBase are used with Scala examples. The graph-based processing is examined using Tinkerpop and Gremlin-based scripts. Using a simple, example-based approach, both: the architecture involved, and multiple ways of using Gremlin shell are introduced in the following diagram:
Spark H2O
While Apache Spark is highly functional and agile, allowing data to move easily between its modules, how might we extend it? By considering the H2O product from http://h2o.ai/, the machine learning functionality of Apache Spark can be extended. H2O plus Spark equals Sparkling Water. Sparkling Water is used to create a deep learning neural processing example for data processing. The H2O web-based Flow application is also introduced for analytics, and data investigation.
Spark Databricks
Having created big data processing clusters on the physical machines, the next logical step is to move processing into the cloud. This might be carried out by obtaining cloud-based storage, using Spark as a cloud-based service, or using a Spark-based management system.
The people who designed Apache Spark have created a Spark cloud-based processing platform called https://databricks.com/. He has dedicated two chapters in the book to this service, because he feels that it is important to investigate the future trends.
All the aspects of Databricks are examined from the user and cluster management to the use of Notebooks for data processing. The languages that can be used are investigated as the ways of developing code on local machines, and then they can be moved to the cloud, in order to save money. The data import is examined with examples, as is the DbUtils package for data processing.
The REST interface for the Spark cloud instance management is investigated, because it offers integration options between your potential cloud instance, and the external systems. Finally, options for moving data and functionality are investigated in terms of data and folder import/export, along with library import, and cluster creation on demand.
Databricks visualisation
The various options of cloud-based big data visualization using Databricks are investigated. Multiple ways are described for creating reports with the help of tables and SQL bar graphs. Pie charts and world maps are used to present data. Databricks allows geolocation data to be combined with your raw data to create geographical real-time charts. The following figure, taken from the book, shows the result of a worked example, combining GeoNames data with geolocation data. The color coded country-based data counts are the result.

It's difficult to demonstrate this in a book, but imagine this map, based upon the stream-based data, and continuously updating in real time. In a similar way, it is possible to create dashboards from your Databricks reports, and make them available to your external customers via a web-based URL.
Summary
Mike hopes that this article has given you an idea of the book's contents. And also that it has intrigued you, so that you will search out a copy of the Spark-based book, Mastering Apache Spark, and try out all of these examples for yourself. The book comes with a code package that provides the example-based sample code, as well as build and execution scripts. This should provide you with an easy start, and a platform to build your own Spark based-code.
Resources for Article:
Further resources on this subject:

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand














